
Resume & Portfolio
Senior year Data Analytics Major | President of Data Analytics Student Association | Division 1 Swimmer | Queens Univeristy of Charlotte
Multilingual Customer Support Ticket Classification Using SVM
Authors: Matej Dusa & Ondrej Dusa
Introduction
In an increasingly globalized business environment, customer support teams must efficiently manage and categorize support tickets submitted in multiple languages. Our project leverages Support Vector Machines (SVM) to classify customer support tickets in both English and German, aiming to streamline ticket triage and improve response times. This essay presents our methodology, findings, and a critical evaluation of model performance, integrating the latest experimental results.
Our team selected the “Learn and apply a new method” option, focusing on SVMs, a technique not previously covered in our coursework. SVMs are well-suited for high-dimensional data like text because they seek optimal boundaries between classes, making them robust for classification tasks. We chose a public dataset of multilingual customer support tickets from Kaggle, which contains ticket subjects, bodies, responses, and metadata (such as type, priority, language, and tags). This dataset’s diversity and complexity provided an excellent testbed for both our technical and analytical skills.
Project Context and Motivation
The core challenge addressed is the automatic classification of multilingual customer support tickets into categories such as “Billing and Payments,” “Technical Support,” and others. Manual sorting is slow and error-prone, especially with high ticket volumes and language diversity. By automating this process, organizations can allocate resources more efficiently and enhance customer satisfaction.
Methodology & Model
Support Vector Machines (SVM):
Support Vector Machines are powerful supervised learning models used for classification and regression tasks. SVMs aim to find the optimal hyperplane that best separates different classes in a dataset by maximizing the margin between the classes’ closest points, known as support vectors. The model can use different kernel functions (e.g., linear, polynomial, radial basis function) to map data into higher-dimensional spaces, enabling it to handle non-linear relationships between features and classes. By focusing on margin maximization, SVMs are effective at generalizing to unseen data and are relatively robust to overfitting, making them particularly useful in high-dimensional spaces.
Process
Data Preparation: We used a public dataset of customer support tickets, containing both English and German entries. Each ticket included textual fields (subject, body, answer) and categorical metadata (type, queue, priority, language, tags).
Feature Engineering: Text data was vectorized using TF-IDF, while categorical features were one-hot encoded. To address class imbalance, SMOTE was applied.
Model Selection: We implemented SVM classifiers for each language, optimizing hyperparameters such as kernel type and regularization strength.
Evaluation: Models were assessed using accuracy, top-2 accuracy, precision, recall, and F1-score, with detailed breakdowns by ticket category.
Results
English Model Performance
- Overall Accuracy: 64.4%
- Top-2 Accuracy: 76.7%
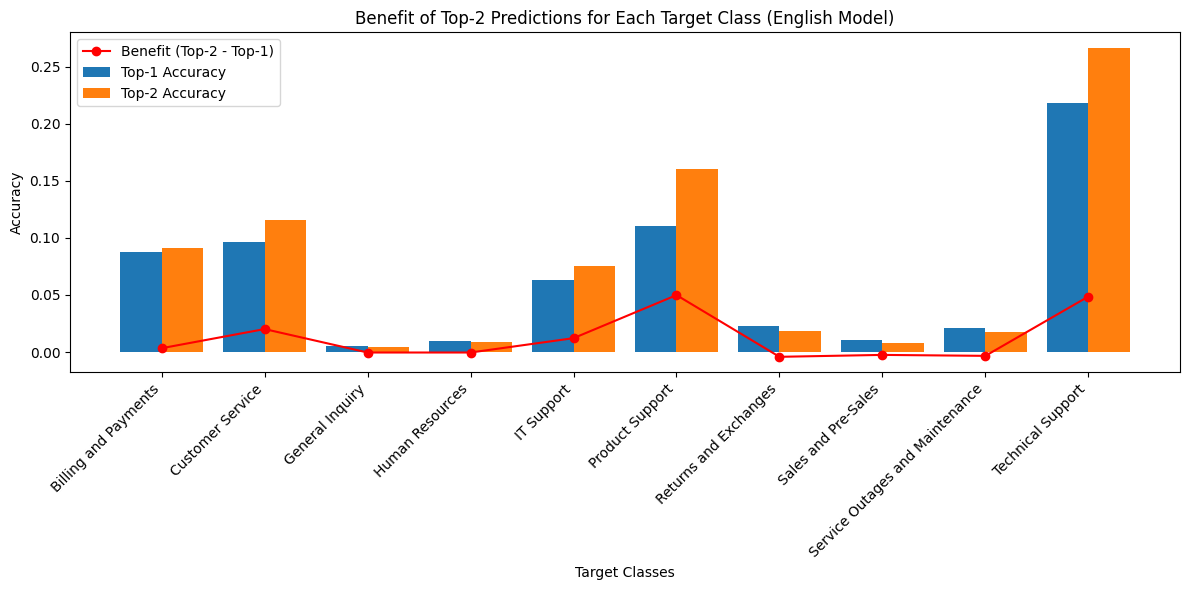
Insights:
The English model performed best on well-defined categories like “Billing and Payments” and “Technical Support,” achieving F1-scores above 0.7. Performance was weaker on underrepresented or ambiguous categories, such as “General Inquiry” and “Sales and Pre-Sales,” with lower recall indicating missed classifications.
German Model Performance
- Overall Accuracy: 48.8%
- Top-2 Accuracy: 66.4%
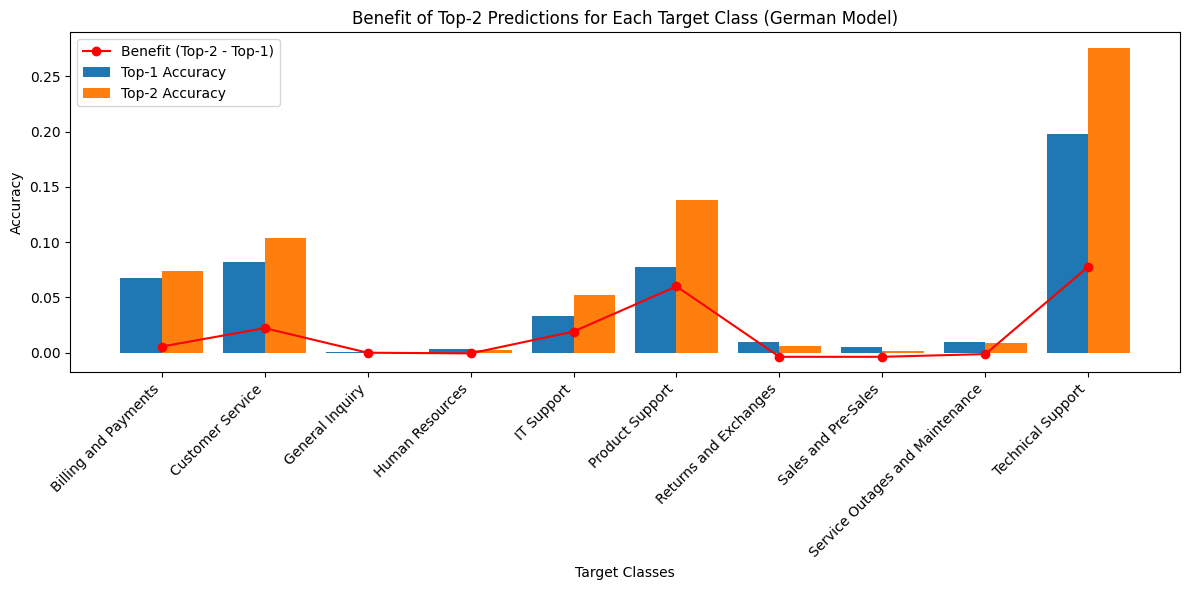
Insights:
The German model struggled, especially in categories with few samples (e.g., “General Inquiry” F1-score: 0.08). Even in better-represented categories, F1-scores were generally lower than in English, highlighting challenges in feature extraction and class imbalance for German-language data.
Discussion
Strengths:
The English SVM model demonstrates strong classification ability in major categories, supporting its practical use for English-language support systems. Top-2 accuracy is notably higher than top-1, suggesting the model often ranks the correct category among its top predictions.
Weaknesses:
The German model’s lower performance reveals limitations in current preprocessing and data representation, particularly for low-frequency classes. Both models show reduced recall in minority or ambiguous categories, indicating a need for richer features or more sophisticated NLP techniques.
Limitations:
Imbalanced class distribution, especially in German, likely affected model learning despite SMOTE. TF-IDF may not capture nuanced linguistic features in German, such as compound words or inflections.
Recommendations
- Enhance preprocessing for German (e.g., lemmatization, compound splitting).
- Augment German data or use multilingual embeddings to improve feature representation.
- Explore alternative models (e.g., deep learning, transformer-based architectures) for better handling of linguistic diversity.
- Incorporate additional ticket fields (subject, tags) to provide more context.
Conclusion
This project demonstrates the viability of SVMs for multilingual customer support ticket classification, with robust performance in English and clear areas for improvement in German. The results underscore the importance of language-specific preprocessing and data balancing in real-world NLP applications. Future work should focus on advanced feature engineering and model architectures to bridge the performance gap across languages.