
Resume & Portfolio
Senior year Data Analytics Major | President of Data Analytics Student Association | Division 1 Swimmer | Queens Univeristy of Charlotte
Exploratory Data Analysis (EDA) of MPG Dataset
This project conducts an Exploratory Data Analysis (EDA) on a dataset containing vehicle fuel efficiency (MPG), acceleration, and various car attributes. The analysis applies statistical techniques to summarize data, detect patterns, and visualize relationships.
Methodology
1. Data Collection
- Reads the
mpg-Ondrej_Dusa.csvdataset into a Pandas DataFrame. - Displays the first few rows for an initial inspection.
mpg = pd.read_csv('mpg.csv')
mpg.head()
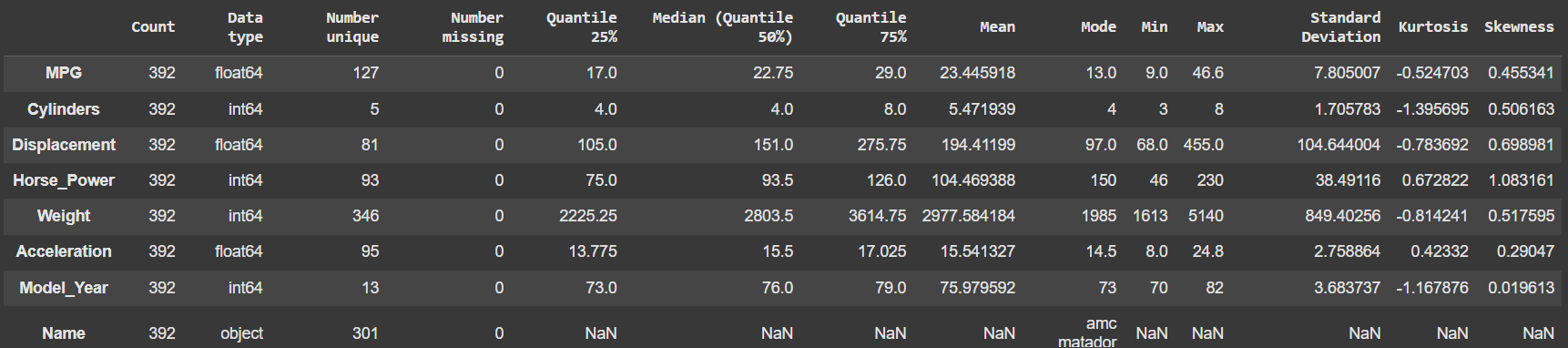
2. Descriptive Statistics
- Computes key summary statistics for categorical and numerical columns.
- Measures include count, mean, median, quantiles, mode, standard deviation, skewness, and kurtosis.
def compute_mode(series):
mode_val = series.mode()
return mode_val.iloc[0] if not mode_val.empty else np.nan
desc_stat = {}
for col in mpg.columns:
if mpg[col].dtype == "object":
desc_stat[col] = {
"Count": mpg[col].count(),
"Data type": mpg[col].dtype,
"Number unique": mpg[col].nunique(),
"Number missing": mpg[col].isna().sum(),
"Mode": mpg[col].mode()[0] if not mpg[col].mode().empty else np.nan,
}
else:
desc_stat[col] = {
"Count": mpg[col].count(),
"Data type": mpg[col].dtype,
"Number unique": mpg[col].nunique(),
"Number missing": mpg[col].isna().sum(),
"Quantile 25%": mpg[col].quantile(0.25),
"Median (Quantile 50%)": mpg[col].median(),
"Quantile 75%": mpg[col].quantile(0.75),
"Mean": mpg[col].mean(),
"Mode": mpg[col].mode().iat[0],
"Min": mpg[col].min(),
"Max": mpg[col].max(),
"Standard Deviation": mpg[col].std(),
"Kurtosis": kurtosis(mpg[col], nan_policy="omit"),
"Skewness": skew(mpg[col], nan_policy="omit"),
}
desc_stat = pd.DataFrame(desc_stat).T
desc_stat
3. Visualization
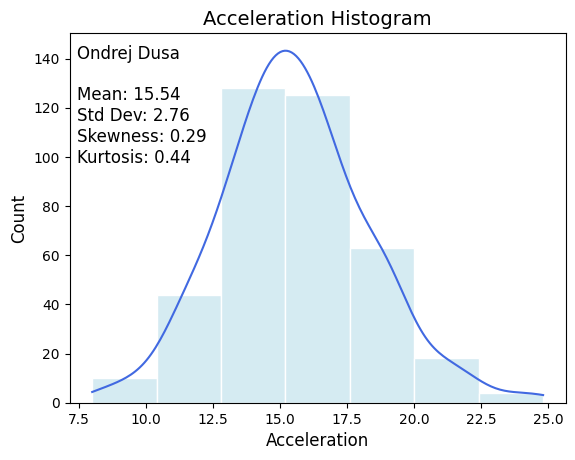
Acceleration Distribution
- Creates a histogram of vehicle acceleration with optimal bin count using the Freedman-Diaconis rule.
- Displays mean, standard deviation, skewness, and kurtosis.
n = len(mpg["Acceleration"].dropna())
bin_count = int(round(n ** (1/3)))
sns.histplot(mpg["Acceleration"], bins=bin_count, kde=True, color="lightblue", edgecolor="white").lines[0].set_color("royalblue")
text_str = (f"Ondrej Dusa\n"
f"\nMean: {mpg['Acceleration'].mean():.2f}\n"
f"Std Dev: {mpg['Acceleration'].std():.2f}\n"
f"Skewness: {mpg['Acceleration'].skew():.2f}\n"
f"Kurtosis: {mpg['Acceleration'].kurt():.2f}")
plt.text(mpg["Acceleration"].max() * 0.3, plt.ylim()[1] * 0.65, text_str, fontsize=12)
plt.title("Acceleration Histogram", fontsize=14)
plt.xlabel("Acceleration", fontsize=12)
plt.ylabel("Count", fontsize=12)
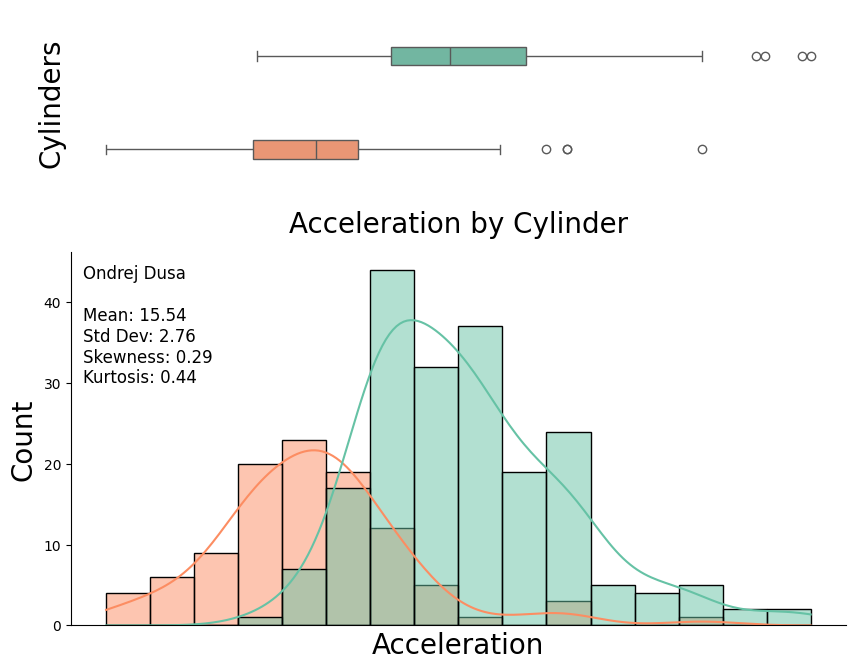
Acceleration by Cylinder Count
- Compares acceleration distribution across 4-cylinder and 8-cylinder vehicles.
- Uses a combination of boxplots and histograms to illustrate differences.
mpg_filtered = mpg[mpg["Cylinders"].isin([4, 8])]
fig, ax = plt.subplots(2, 1, figsize=(10, 8), gridspec_kw={'height_ratios': [1, 2]}, sharex=True)
sns.boxplot(x="Acceleration", y="Cylinders", data=mpg_filtered, ax=ax[0], orient="y", palette="Set2", width=0.2)
ax[0].set_ylabel("Cylinders", fontsize=20)
ax[0].text(0.5, -0.15, "Acceleration by Cylinder", ha='center', va='center', fontsize=20, transform=ax[0].transAxes)
sns.histplot(data=mpg_filtered, x="Acceleration", hue="Cylinders", bins=16, kde=True, ax=ax[1], palette="Set2", legend=False)
ax[1].set_xlabel("Acceleration", fontsize=20)
ax[1].set_ylabel("Count", fontsize=20)
sns.despine(ax=ax[0], left=True, bottom=True)
sns.despine(ax=ax[1], top=True, right=True)
ax[0].set_xticks([])
ax[0].set_yticks([])
text_str = (f"Ondrej Dusa\n"
f"\nMean: {mpg['Acceleration'].mean():.2f}\n"
f"Std Dev: {mpg['Acceleration'].std():.2f}\n"
f"Skewness: {mpg['Acceleration'].skew():.2f}\n"
f"Kurtosis: {mpg['Acceleration'].kurt():.2f}")
plt.text(mpg["Acceleration"].max() * 0.3, plt.ylim()[1] * 0.65, text_str, fontsize=12)
Technologies Used
Python– Data analysis and visualizationPandas– Data manipulationNumPy– Numerical computationsSciPy– Statistical analysis (skewness, kurtosis)Matplotlib & Seaborn– Data visualization
Key Insights
- The dataset contains a mix of numerical and categorical data, requiring different analytical techniques.
- Acceleration follows a right-skewed distribution, with notable differences between 4-cylinder and 8-cylinder vehicles.
- Skewness and kurtosis metrics highlight deviations from normality, suggesting that transformations or non-parametric methods may be necessary for further modeling.
This project demonstrates a structured approach to data exploration, leveraging descriptive statistics and visualization techniques to uncover insights from real-world datasets.