
Resume & Portfolio
Senior year Data Analytics Major | President of Data Analytics Student Association | Division 1 Swimmer | Queens Univeristy of Charlotte
Email Classification Using Multinomial Naive Bayes
Overview
This project focuses on classifying emails into categories based on their content, utilizing a Multinomial Naive Bayes classifier. The goal is to preprocess and clean email data, then train a model to predict labels for new emails. The analysis includes text preprocessing, feature extraction using CountVectorizer, and evaluation of model performance with a classification report.
Methodology
Data Collection
- Loads a dataset of emails stored in a TSV file using Pandas.
- The dataset consists of email content and their corresponding labels (e.g., spam or not spam).
- The data is accessed through Google Colab by mounting Google Drive.
Text Preprocessing
- Missing Values: Handles missing values in the ‘text’ column by replacing them with empty strings.
- Lowercasing: Converts all text to lowercase to ensure uniformity.
- Special Character Removal: Removes non-alphanumeric characters using regular expressions.
- Stopwords Removal: Filters out common English stopwords (e.g., “the”, “and”).
- Stemming: Applies the PorterStemmer to reduce words to their root forms (e.g., “running” becomes “run”).
- Text Transformation: Processes the email content into cleaned text that will be used for modeling.
Feature Extraction
- Utilizes CountVectorizer to convert the processed text into a bag-of-words representation.
- This step transforms the emails into numerical features that can be input into the classifier.
Model Training
- Splits the dataset into training (70%) and testing (30%) sets using train_test_split.
- A Multinomial Naive Bayes model is trained on the training data.
- The model is then used to make predictions on the test data.
Model Evaluation
- The model’s performance is evaluated using the classification report, which provides key metrics like precision, recall, F1-score, and accuracy.
- The classification report helps assess how well the model classifies emails into their respective categories.
Technologies Used
PythonProgramming LanguagePandas– Data handling and manipulationNLTK– Natural language processing (text preprocessing)Scikit-learn– Machine learning (model building and evaluation)Google Colab– Cloud environment for executing and running the code
Key Insights
- The Multinomial Naive Bayes model provides a straightforward approach to text classification and can be effective in spam detection.
- Text preprocessing, including stopwords removal and stemming, plays a crucial role in improving model performance.
- The classification report reveals that there may be room for improvement in terms of model accuracy, especially with small or imbalanced datasets.
Output:
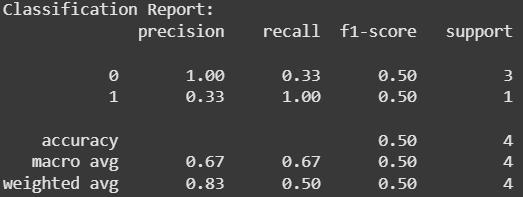
The results of the email classification project show that the Multinomial Naive Bayes model performs with 50% accuracy on the test dataset. The classification report indicates that the model has high precision for class 0 “Normal Email” (1.00) but poor recall (0.33), and vice versa for class 1 “Spam Email” (high recall of 1.00 but low precision of 0.33). The F1-scores for both classes are 0.50, indicating an imbalance between precision and recall. The weighted average F1-score is also 0.50, reflecting the model’s overall performance on the small dataset. While the model provides some useful insights, it suggests room for improvement, especially in handling class imbalance and refining text preprocessing methods.
Code:
nltk.download('stopwords') #Downloaded stop words
emails = pd.read_csv("emails.tsv", sep='\t') #Loaded the TSV file containing my emails.
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
def preprocess_text(text):
emails['text'] = emails['text'].fillna("")
text = str(text).lower()
text = re.sub(r'\W', ' ', text)
words = text.split()
stop_words = set(stopwords.words('english'))
words = [stemmer.stem(word) for word in words if word not in stop_words]
#words = [lemmatizer.lemmatize(word) for word in words if word not in stop_words]
return ' '.join(words)
emails['processed_text'] = emails['text'].apply(preprocess_text) #Applies the pre processing for the emals.
X_train, X_test, y_train, y_test = train_test_split(emails['processed_text'], emails['label'], test_size=0.3, random_state=42)
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
model = MultinomialNB() #Load Multinomial model.
model.fit(X_train_vec, y_train)
y_pred = model.predict(X_test_vec)
print("Classification Report:")
print(classification_report(y_test, y_pred))
Summary
This project demonstrates the application of machine learning for text classification, utilizing natural language processing techniques and a simple probabilistic model to classify emails. It showcases the effectiveness of Multinomial Naive Bayes for text data and provides a foundation for future improvements and more advanced approaches.